Introduction
In this tutorial, Jan-Hendrik demonstrates how to import and analyse the newly added CPI Weights data from EconData in R using the econdatar package. We will split the data into two distinct regimes, following the format provided by Stats SA. The first regime includes data from 1970-2000, while the second regime covers 2008-2019. Although we will not be using it in this tutorial, it’s important to note that the second regime maps the concepts to their respective Classification of Individual Consumption
According to Purpose (COICOP) classifications.
Let’s jump in!
1. First, load necessary packages
We will only be using three:
econdatar(automated importing of data)dplyr(for data manipulation)ggplot(for plotting)
library(econdatar)
library(ggplot2)
library(dplyr)
If you do not have econdatar installed, you can use the following code to install the latest version:
library(devtools)
install_github("coderaanalytics/econdatar")
library(econdatar)
Also see our user guide for more information.
2. Import the data
Let’s import that weights data in a long tidy format. We will be loading the first (1970 as weights_1) and last vintage (2019 as weights_2).
The data has hundreds of series, so we will specifically be working with the highest level of the weights, classified as a ‘division’ or ‘divisional group’. This group refers to the largest grouping in the weights, and is made up for ‘groups’, ‘classes’, and ‘subclasses’. For example, ‘Food’ from 1970 can, for example, be broken down into the group ‘Grain products’, with the class ‘White bread’. See the CPI weights user guide for more detail on the structure of the data.
weights_1 <- read_econdata( id = "CPI_WEIGHTS",
version = "1.0.1",
series_key = "TC.D.",
release = "latest",
tidy = TRUE,
wide = FALSE,
compact = FALSE,
combine = TRUE
) %>%
select(series_key, series_name, division, cpi_basket, time_period, obs_value) %>%
filter(time_period < as.Date("1970-01-02"))
See the arguments from the read_econdata() function? They allow us to specify the format for importing data into R. The default arguments of the function will import the data as a list of time-series objects. This is one of the benefits of using econdatar, as it can structure the data for you in many formats, according to your needs.
weights_2 <- read_econdata( id = "CPI_WEIGHTS",
version = "1.1.1",
series_key = "TC.D.",
release = "latest",
tidy = TRUE,
wide = FALSE,
compact = FALSE,
combine = TRUE
) %>%
select(series_key, series_name, division, cpi_basket, time_period, obs_value) %>%
filter(time_period > as.Date("2018-12-31"))
3. Data formatting
Now that we have loaded the data, you will see that there is not a good overlap between the two regimes’ concept names. This owes to the differing formats of the first and second regimes. We can easily circumvent this issue by using the code below to standardise the names of overlapping concepts.
# Standardize the series_name in weights_1
weights_1 <- weights_1 %>%
mutate(series_name = case_when(
series_name == "Housing" ~ "Housing",
series_name == "Food" ~ "Food and Non-alcoholic beverages",
series_name == "Non-Alcoholic Beverages" ~ "Food and Non-alcoholic beverages",
series_name == "Transport" ~ "Transport",
series_name == "Other Goods and Services" ~ "Miscellaneous goods and services",
series_name == "Alcoholic beverages" ~ "Alcoholic beverages and tobacco",
series_name == "Cigaerettes, Cigars, Tobacco" ~ "Alcoholic beverages and tobacco",
series_name == "Furniture and Equipment" ~ "Household contents, equipment and maintenance",
series_name == "Clothing and Footwear" ~ "Clothing and footwear",
series_name == "Medical and Health Expenses" ~ "Health",
series_name == "Communication" ~ "Communication",
TRUE ~ "All other divisions"
))
# Standardize the series_name in weights_2
weights_2 <- weights_2 %>%
mutate(series_name = case_when(
series_name == "Housing and utilities" ~ "Housing",
series_name == "Food and Non-alcoholic beverages" ~ "Food and Non-alcoholic beverages",
series_name == "Transport" ~ "Transport",
series_name == "Miscellaneous goods and services" ~ "Miscellaneous goods and services",
series_name == "Alcoholic beverages and tobacco" ~ "Alcoholic beverages and tobacco",
series_name == "Household contents, equipment and maintenance" ~ "Household contents, equipment and maintenance",
series_name == "Clothing and footwear" ~ "Clothing and footwear",
series_name == "Health" ~ "Health",
series_name == "Communication" ~ "Communication",
TRUE ~ "All other divisions"
))
The first and second regime have 17 and 12 divisional groups, respectively. That is a lot of groups for one colour palette to handle! To limit the number of categories and simplify the plot, we select some of the largest historic weights, and combine the rest into one category, ‘All other divisions’. Sum the values for categories that need to be combined:
weights_1 <- weights_1 %>%
group_by(time_period, series_name) %>%
summarise(obs_value = sum(obs_value, na.rm = TRUE)) %>%
ungroup()
weights_2 <- weights_2 %>%
group_by(time_period, series_name) %>%
summarise(obs_value = sum(obs_value, na.rm = TRUE)) %>%
ungroup()
4. Data validation
To do some validation, we can check whether the weights add up to 100:
weights_1 %>%
group_by(time_period) %>%
summarise(obs_value = sum(obs_value, na.rm = TRUE))
weights_2 %>%
group_by(time_period) %>%
summarise(obs_value = sum(obs_value, na.rm = TRUE))
This will print the sums of the divisional groups in the R console. Next I merge the two data series into one tibble, for plotting.
combined_weights <- bind_rows(weights_1, weights_2)
5. Plot the data!
Finally we can plot the data. Here we opted for a simple stacked bar chart. First, we define a custom colour palette, inspired by Star Wars:
- Lightsaber Blue: ‘#1976D2’
- Lightsaber Green: ‘#4CAF50’
- Lightsaber Red: ‘#D32F2F’
- Tatooine Sand: ‘#F4A460’
- Death Star Gray: ‘#616161’
- Stormtrooper White: ‘#F5F5F5’
- Yoda Green: ‘#6B8E23’
- Darth Vader Black: ‘#212121’
- R2-D2 Silver: ‘#B0C4DE’
- Rebel Alliance Orange: ‘#FF5722’
color_list <- c("#1976D2", "#4CAF50", "#D32F2F", "#F4A460", "#616161",
"#F5F5F5", "#6B8E23", "#212121", "#B0C4DE", "#FF5722")
# Plot the data
combined_weights %>%
ggplot(aes(x = time_period, y = obs_value, fill = series_name)) +
geom_bar(position = "stack", stat = "identity", color = "black") +
theme_minimal() +
scale_fill_manual(values = color_list) +
scale_x_date(breaks = as.Date(c("1970-01-01", "2019-01-01")),
date_labels = "%Y") +
labs(x = "Time Period",
y = "Weight (%)",
fill = "Division")
The plotting code should produce the following figure:
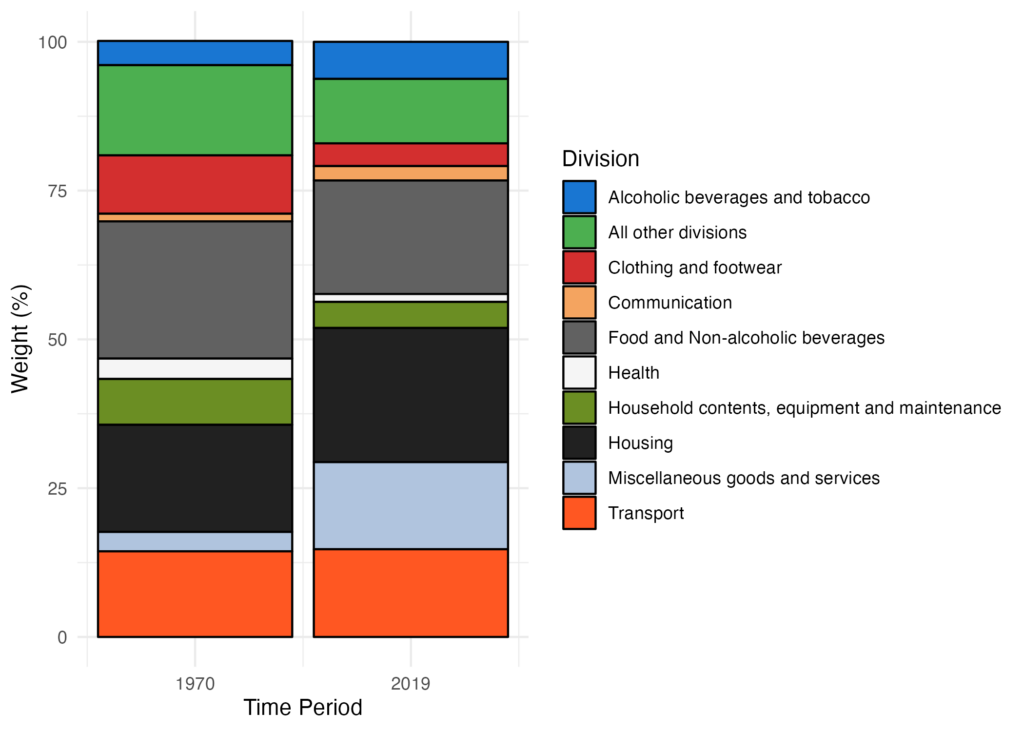
And there you have it. This tutorial only scratches the surface of the vast potential within this dataset to understand consumer spending behavior. Remember, with the econdatar package, you always have access to the latest data from EconData. Be sure to explore other price-related series available on EconData, and refer to our user guide for more insights and tips!